
HBM in AI Systems: Selection, Capacity Planning, and Procurement Guide
A buyer-facing HBM guide for AI systems covering what HBM solves, how to compare HBM2e, HBM3, and HBM3e, where packaging constraints matter, and what procurement teams should verify before treating HBM like ordinary memory.
Quick facts
- HBM is chosen in AI accelerators because bandwidth density and package-level proximity matter more than DIMM-style capacity scaling.
- The first buyer split is not vendor alone but generation, capacity per stack, total package bandwidth, and accelerator-package compatibility.
- HBM should be sourced as part of an accelerator and advanced-packaging ecosystem, not as a standalone commodity DRAM purchase.
- For many practical sourcing conversations, HBM3e is the commercial reference point, while HBM2e and earlier HBM3 remain important for legacy or cost-constrained programs.
Many HBM articles explain the technology well, then stop before the real decision starts. That leaves buyers with the wrong question. The useful question is not "what is HBM?" It is which AI system actually needs HBM, which HBM generation fits the platform, and what should procurement verify before a memory decision becomes a packaging and lead-time problem.
This article is written for that decision point. It treats HBM as part of an AI accelerator system, not as a generic DRAM upgrade. The right frame is bandwidth, package architecture, capacity planning, and supply continuity.
1. What HBM actually solves in AI systems
fact HBM is built from vertically stacked DRAM dies connected through TSV structures and a very wide interface. TC judgment That physical structure matters because AI accelerators are often limited by how quickly data can move between compute and memory, not only by how many compute units are available.
The difference from DDR-style memory is architectural:
| Memory class | Best at | Where it struggles in AI systems |
|---|---|---|
| DDR | General server memory expansion and platform flexibility | Package-level bandwidth density is limited for accelerator-heavy workloads |
| GDDR | High-throughput graphics and some accelerator use cases | Board-level routing and power tradeoffs become harder at extreme AI bandwidth targets |
| HBM | Very high bandwidth close to the processor package | Cost, packaging dependence, and supply concentration are all materially harder |
TC judgment That is why HBM belongs in systems where bandwidth density is the bottleneck. It is not the automatic answer for every AI or HPC design.
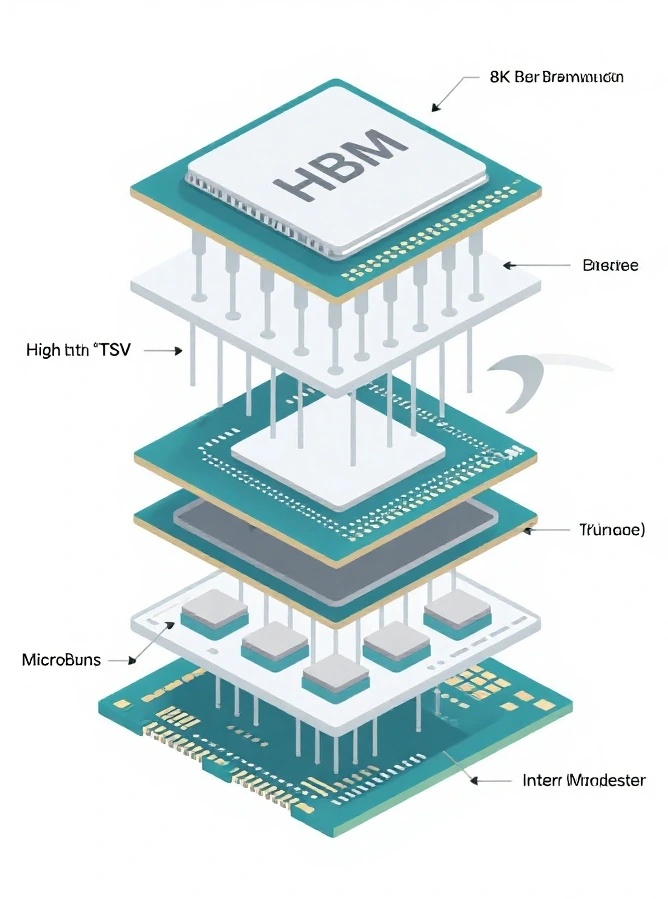
2. The first buyer split: platform fit before vendor preference
The most common HBM buying mistake is starting with the supplier name instead of the platform boundary.
For a real program, procurement should check four things first:
| Decision area | What to verify | Why it matters |
|---|---|---|
| Generation | HBM2e, HBM3, HBM3e, or future HBM4 target | Sets the baseline for bandwidth, density, and platform expectation |
| Capacity per stack | How much memory each stack contributes | Affects model fit, local working set, and package budget |
| Total package bandwidth | The aggregate bandwidth across the accelerator package | Determines whether the system is solving the actual memory bottleneck |
| Package compatibility | Interposer, substrate, thermals, and accelerator roadmap | HBM is inseparable from advanced packaging decisions |
TC judgment A buyer who treats HBM as "just faster DRAM" is already one step behind the actual design constraint.
3. Which HBM generation usually fits which program
It is better to think in decision lanes than in hype cycles.
| Generation | Best-fit program posture | Buyer reading |
|---|---|---|
| HBM2e | Legacy accelerators, continuity buys, or controlled-cost platforms | Suitable when the platform is already qualified and bandwidth targets are modest by current AI standards |
| HBM3 | Transitional or mid-generation accelerator platforms | Useful where the package is fixed and the program needs a step up without chasing the newest lane |
| HBM3e | Main commercial reference point for newer AI accelerator planning | Strong fit for bandwidth-heavy training and inference platforms with current roadmap alignment |
| HBM4 | Forward planning only for most buyers | Relevant to roadmap and qualification timing more than spot procurement today |
TC judgment This is the practical HBM3e framing: it is not "better because newer." It is better when the program is genuinely bandwidth-limited and the package ecosystem is already built for it.
4. Capacity planning is a system question, not a memory question
HBM capacity decisions are often presented as if the memory itself is the whole story. In practice, the buyer is funding a compute-memory package strategy.
The capacity conversation usually comes from three workloads:
- model weights that must stay local to the accelerator
- activation and intermediate data that expand under training or large-batch inference
- optimizer or checkpoint overhead in training-oriented systems
TC judgment The right question is not "how many gigabytes per stack look impressive?" The right question is "what local-memory envelope does this platform need before data movement becomes the real bottleneck again?"
That is why two accelerator programs can reach opposite answers even when both say they are "for AI":
| Program type | Typical memory pressure | HBM consequence |
|---|---|---|
| Training-heavy accelerator | Very high bandwidth and large local working sets | HBM generation and total stack count become central decisions |
| Inference-focused platform | May still need HBM, but cost efficiency matters more | Older qualified HBM lanes may remain attractive |
| Edge AI or compact accelerator | Thermal and package limits may dominate | HBM may be overkill unless the application is strongly bandwidth-bound |
5. Supplier choice is inseparable from packaging and roadmap
fact Commercial HBM supply is concentrated among a small set of major memory manufacturers. TC judgment That concentration means supplier choice is not just a catalog preference. It affects roadmap timing, package enablement, qualification cadence, and negotiation leverage.
For buyers, the practical supplier questions are:
- Which HBM generation is actually aligned with the target accelerator package?
- Does the supplier's roadmap match the program's launch timing?
- Is the package ecosystem already enabled for that memory lane?
- What is the realistic lead-time posture, not the nominal one?

TC judgment This is where HBM stops looking like normal memory procurement and starts looking like ecosystem procurement.
6. Why HBM procurement is not ordinary DRAM procurement
With conventional server memory, a buyer may focus on density, speed bin, AVL status, and channel availability. HBM adds another layer: the memory sits inside an advanced-package decision that may already constrain the entire accelerator program.
Use this review stack before approving an HBM path:
- Confirm the accelerator platform and package lane first.
- Verify which HBM generation that platform was designed or qualified around.
- Check whether the local-memory target is driven by training, inference, or continuity support.
- Validate total bandwidth, not just per-stack marketing numbers.
- Review thermals, power, and package-level feasibility with the engineering team.
- Treat supplier roadmap and lead time as core risk inputs, not as afterthoughts.
TC judgment If those six checks are not complete, the procurement decision is still too early.
7. A practical buyer framework by use case
| Use case | Best starting question | Likely HBM reading |
|---|---|---|
| New AI accelerator design | What package and bandwidth target is fixed by the roadmap? | Often starts in HBM3e discussions if the platform is current-generation |
| Legacy platform support | Is continuity more important than headline speed? | HBM2e or earlier HBM3 lanes may still be the commercially correct answer |
| Data-center training cluster | Is local bandwidth the limiting resource? | HBM becomes central, not optional |
| Cost-controlled inference platform | Does the workload justify premium packaging and memory cost? | HBM may still fit, but only if the bandwidth benefit is real |
Bottom line
HBM matters in AI systems because it solves a package-level bandwidth problem that ordinary memory architectures often cannot solve cleanly. That does not make it a generic upgrade. The useful buying decision is generation plus capacity plus package compatibility plus lead-time reality.
If your team is evaluating HBM for a live AI platform, treat the memory stack, the package ecosystem, and the supplier roadmap as one procurement problem. That is the point where good HBM decisions stop being memory decisions alone.
